- Image/Video Storage, Retrieval
- Image/Video Processing
- Image/Video Coding
- Image Scanning, Display, and Printing
- Image Formation

- Read more about Spatial Keyframe Extraction of Mobile Videos for Efficient Object Detection at the Edge
- Log in to post comments
Advances in federated learning and edge computing advocate for deep learning models to run at edge devices for video analysis. However, the captured video frame rate is too high to be processed at the edge in real-time with a typical model such as CNN. Any approach to consecutively feed frames to the model compromises both the quality (by missing important frames) and the efficiency (by processing redundantly similar frames) of analysis.
ICIP2020.pdf
- Categories:
 14 Views
14 Views
- Read more about PerceptNet: A Human Visual System Inspired Neural Network for Estimating Perceptual Distance
- Log in to post comments
Traditionally, the vision community has devised algorithms to estimate the distance between an original image and images that have been subject to perturbations. Inspiration was usually taken from the human visual perceptual system and how the system processes different perturbations in order to replicate to what extent it determines our ability to judge image quality. While recent works have presented deep neural networks trained to predict human perceptual quality, very few borrow any intuitions from the human visual system.
- Categories:
13 Views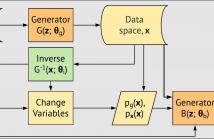
- Read more about Boundary of Distribution Support Generator (BDSG): Sample Generation on the Boundary
- Log in to post comments
- Categories:
105 Views
- Read more about Always Look on the Bright Side of the Field: Merging Pose and Contextual Data to Estimate Orientation of Soccer Players [Slides]
- Log in to post comments
SlidesICIP.pdf
- Categories:
13 Views
- Read more about Deep-URL
- Log in to post comments
The lack of interpretability in current deep learning models causes serious concerns as they are extensively used for various life-critical applications. Hence, it is of paramount importance to develop interpretable deep learning models. In this paper, we consider the problem of blind deconvolution and propose a novel model-aware deep architecture that allows for the recovery of both the blur kernel and the sharp image from the blurred image.
- Categories:
37 Views
- Read more about MULTI IMAGE DEPTH FROM DEFOCUS NETWORK WITH BOUNDARY CUE FOR DUAL APERTURE CAMERA
- Log in to post comments
In this paper, we estimate depth information using two defocused images from dual aperture camera. Recent advances in deep learning techniques have increased the accuracy of depth estimation. Besides, methods of using a defocused image in which an object is blurred according to a distance from a camera have been widely studied. We further improve the accuracy of the depth estimation by training the network using two images with different degrees of depth-of-field.
- Categories:
25 Views
- Read more about IMPROVING THE PERFORMANCE OF TRANSFORMER BASED LOW RESOURCE SPEECH RECOGNITION FOR INDIAN LANGUAGES
- Log in to post comments
The recent success of the Transformer based sequence-to-sequence framework for various Natural Language Processing tasks has motivated its application to Automatic Speech Recognition. In this work, we explore the application of Transformers on low resource Indian languages in a multilingual framework. We explore various methods to incorporate language information into a multilingual Transformer, i.e.,(i) at the decoder, (ii) at the encoder. These methods include using language identity tokens or providing language information to the acoustic vectors.
shetty.pdf
- Categories:
50 Views
- Read more about INTERPRETABLE SELF-ATTENTION TEMPORAL REASONING FOR DRIVING BEHAVIOR UNDERSTANDING
- Log in to post comments
Performing driving behaviors based on causal reasoning is essential to ensure driving safety. In this work, we investigated how state-of-the-art 3D Convolutional Neural Networks (CNNs) perform on classifying driving behaviors based on causal reasoning. We proposed a perturbation-based visual explanation method to inspect the models' performance visually. By examining the video attention saliency, we found that existing models could not precisely capture the causes (e.g., traffic light) of the specific action (e.g., stopping).
- Categories:
35 Views
- Read more about Parsing Map Guided Multi-Scale Attention Network For Face Hallucination
- Log in to post comments
4929wang.pdf
- Categories:
29 Views
- Read more about IMAGE SEGMENTATION BASED PRIVACY-PRESERVING HUMAN ACTION RECOGNITION FOR ANOMALY DETECTION
- Log in to post comments
- Categories:
48 Views